

OpenAI добавила новую функцию генерации изображений в ChatGPT на базе модели GPT-4o. Функция доступна всем пользователям, в том числе на бесплатных тарифных планах.
Ключевые особенности новой функции – система лучше понимает контекст разговора при создании изображений, понимает сложные инструкции, может генерировать четкий текст на картинках. Благодаря обновлению пользователи смогут получать более точные и релевантные изображения.
Генерация изображений с помощью GPT‑4o обеспечивает точное воспроизведение текста, следование промптам, использует базу знаний 4o и контекст чата, включая преобразование загруженных изображений или использование их в качестве визуального источника вдохновения. Эти возможности позволяют создать именно то изображение, которое вы себе представляете, помогают эффективнее взаимодействовать через визуал и превращают генерацию изображений в практический инструмент, обладающий точностью и мощью.
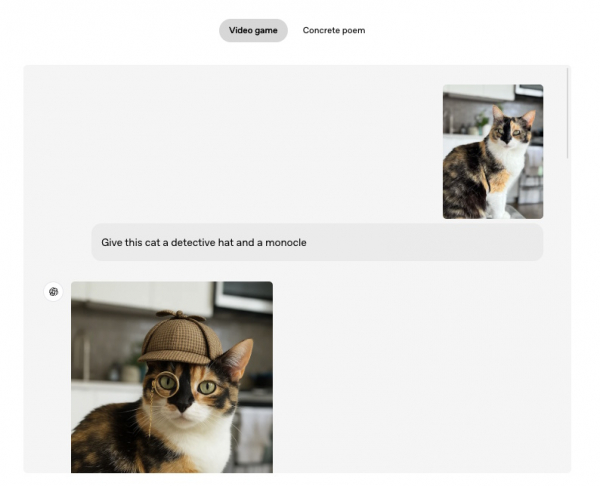
Пользователи могут вносить правки в генерируемые изображения, например, убирать или добавлять какие-то элементы.

Поскольку генерация изображений теперь встроена в GPT‑4o, вы можете улучшать изображения в ходе общения. GPT‑4o может создавать изображения и текст, учитывая контекст и обеспечивая согласованность действий. Например, если вы разрабатываете персонажа для видеоигры, его внешний вид остается неизменным на протяжении нескольких итераций по мере того, как вы совершенствуете его и экспериментируете.
В компании отмечают, что несмотря на все преимущества, модель все еще несовершенна. Например, она может галлюцинировать (то есть выдавать ложную информацию). Также есть сложности с отображением нелатинских символов и сохранением последовательности при генерации лиц.
Из-за высоких требований к обработке генерация изображений занимает в среднем около одной минуты.
Напомним, ранее Google сообщил о том, что выпустил экспериментальную версию «рассуждающей» модели Gemini 2.5 Pro.
Комментарии закрыты.